Here we go ..

Prata. The king of foods. Best served hot and slightly crispy, with a masala curry and sweet teh tarik. Its cheap..
quick.. satisfying..
That's what this blog is going to be about. Its my place to post quick satisfying stuff, no subject out of bounds.
read more and comment..
Log Buffer #54: a Carnival of the Vanities for DBAs
This week its my pleasure to host Log Buffer #54, the Carnival of the Vanities for DBAs. Thanks to Dave Edwards at
Pythian for the invite to put this together. Dave must be a very chilled
sorta guy to be able to survive each Friday, not knowing what on earth his guest editor is going to churn
out!!
Of course 11g continues to be a big topic this week.
Dan Norris adds his views on the best 11g new features to the
flurry that came out last week. Christian Bilien's having a party to celebrate ASM
fast mirror resync. Syed Jaffar Hussain discovers the alert log will now be XML. Personally I shudder; still not
convinced that XML is appropriate for log files.
It strikes me that in this period between launch and release, there's more eyeballs on docs that at any other
time in the product lifecycle;)
NB: There still seems to be some
confusion whether we are meant to know when 11g will arrive or not. Steven Chan's older post almost convinced me there's a good reason why we don't
hear dates;)
In the SQL Server world, Kalen Delaney blogs in wonderment having discovered the
dialog box that time forgot. And Bob Beauchemin has some good SQL Server book reviews.
While on book reviews, Stewart Smith is impressed by O'Reilly's Backup &
Recovery because it covers just about every way to back up and recover systems (I trust not this way).
So did PostgreSQL trounce Oracle or not? Kevin Closson
exposed the lazy reporting that seems to have sparked this "non-story". But you know how pointless it is to try and
correct the facts once they are out on the net, right?
Its a pity for the controversy, because as Jay
Pipes writes, the benchmark achievement is no mean feat for the PG dev team.
Lots of interseting stuff on mysql this week. Mats Kindahl takes mysql proxy for a decent test drive, concludes it has great
potential and offers some constructive comments on gaps to be filled. The MySQL 5 HA with DRDB and
Heartbeat guide is very well put together by Mark Schoonover (who blurs the line between blog post and technical
reference guide!)
What do I like most about open source? Take something like Jay Pipes internals
of MyISAM Concurrent insert (part 1 posted this week). Great example of hard core geek writings. Can you ever
imagine Oracle, IBM or Microsoft getting down and dirty on internals like this? I love it!
Moving on to deeper thoughts...
K. Brian Kelley mulls over what it means to be a dba, but
might be surprised that Patrick Wolf stumbled across an 11g feature that means DBA's may put Java/SOA guys out of
work.
Doug Burns ponders just how many blogs a person should have, and
in the process gave quite a few pause for thought.
Over in the Oracle Forums, activity seems
to be at a high but one wonders about the signal to noise. I think Sidhu was remarkably restrained when I
think my response may just have been jfgi!
... and that's pretty much a wrap for this week. Thanks for reading my first attempt at editing the Log Buffer. It just
remains for me to leave you with my lame attempt at a bit of 11g humour. Keep on blogging!

read more and comment..
Check LOCAL_LISTENER if you run RAC!
Had a case recently with a 10gR2 RAC install. Everything seemed to have been setup to spec, but we were seeing clients
occasionally getting ORA-12545 errors and failing to connect, and things getting even worse during failover
testing.
After investigating and solving this, it was painfuly obvious how easy the configuration issue can sneak into a RAC
install, which prompts me to blog about it now. Bottom line: if you are installing RAC or are responsible for managing
a RAC database, I strongly suggest you swivel over right now and 'show parameter LISTENER'!
So back to our case.... looking at a sqlnet client trace, it was apparent that the client was being redirected to the
server hostname, not one of the RAC virtual addresses. Two problems:
- the client couldn't resolve the server hostname since it wasn't in DNS or the client hosts file, and
- the client shouldn't be connecting to the server hostname anyway!
The client tnsnames.ora and the servers' tnsnames.ora and listener.ora files had all been checked and were setup with only references the the RAC virtual addresses, so where was the reference to the 'physical' hostname coming from? Well the answer is the LOCAL_LISTENER server parameter.
You would think however that if your client connection descriptor (taken from tnsnames.ora for example) only referenced virtual addresses, you would be safe, right? Not the case, and having a solid understanding of how the listener works is critical to knowing why.
The problem stems from the way that in 10g instances automatically register with the listener, and it is very easy to fall into this trap if you haven't paid very close attention to section "9 Understanding the Oracle Real Application Clusters Installed Configuration" in the platform-specific cluster installation guides.
If you have a DEDICATED server config, then the LOCAL_LISTENER parameter is used for the instance registration with the listener. If you are using a default listener on port of 1521, then DBCA will not automatically set the LOCAL_LISTENER. Section "9.8 Configuring the Listener File (listener.ora)" describes how to manually set a correct LOCAL_LISTENER value, but if you haven't done that, it will default to a connection string that refers to the physical host address (not virtual address).
But you might think "connecting to the physcial host address can't be too bad, can it?". Well yes, there are two problems you can see:
- Clients may not be able to resolve the host address if you don't have that in DNS, and more importantly
- In a failover situation, clients will not follow the virtual IP.
Even then, you might think this would be a very rare problem, because client's tnsnames or other naming is always telling them to connect to the virtual address anyway.
Again, not so. It can be very common for the client to get a connection to the physical host address even if the tnsnames tells them to connect to the virtual address, because of RAC workload management and listener redirects.
Lets take an example of a RAC service called SVC with two instances SVC1 and SVC2 running on host1 and host2 (with virtual addresses host1_vip and host2_vip). The client tnsnames would look something like this:
SVC =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = host1_vip)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = host2_vip)(PORT = 1521))
(LOAD_BALANCE = yes)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = SVC)
(FAILOVER_MODE=(TYPE=select)(METHOD=basic)(RETRIES=10)(DELAY=1))
)
)
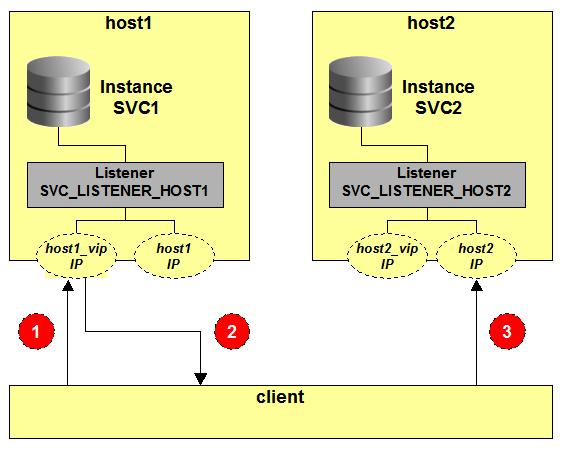
The diagram shows how a connection is handled through the listener in the case where the LOCAL_LISTENER is not set correctly. The flows go like this:
- The client selects a virtual host from the address list and attempts a connection, in this case to the listener
on host1_vip.
- The listener selects a preferred instance to handle the session for the service SVC. If the local SVC1 instance
is down, or if it thinks instance SVC2 is better able to service the request it sends a listener redirect to the
client. This redirect will be to the physical hostname (host2)
- If the client is not able to resolve "host2", you will see an ORA-12545 at this point. If it can resolve the
address, then the client establishes a connection to the listener on the host2 address. If SVC2 is running, you
should now have a good connection to the database. However, consider now what happens if host2 fails. CRS will ensure
that the host2_vip will shift over to host1, but the client is connected to host2 address and you will get into a TCP
timout situation. Maybe your client will eventually detect the dead connection and attempt to reconnect (using VIPs),
but at best the user application will have stuttered for a significant period of time (depending on your tcp and
sqlnet settings).
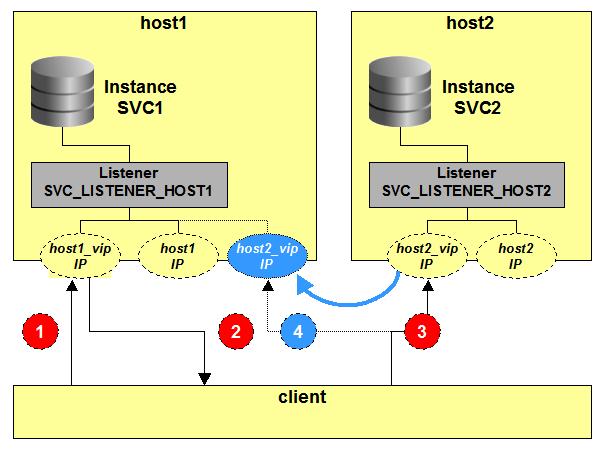
Now consider what should happen, with a correctly configured LOCAL_LISTENER.
- The client selects a virtual host from the address list and attempts a connection, in this case to the listener
on host1_vip.
- The listener selects a preferred instance to handle the session for the service SVC. If the local SVC1 instance
is down, or if it thinks instance SVC2 is better able to service the request it sends a listener redirect to the
client. This redirect will be to the virtual hostname (host2_vip)
- We get a good connection established to SCV2 on host2_vip. Again, consider now what happens if host2 fails.
- CRS will ensure that the host2_vip will shift over to host1, and the client connection follows this VIP. There
will be a slight interruption to communication (depending on how quickly the VIP take-over occurs, and also other
factors such if you are connecting through a NAT router, the NATting tables will need to update). Depending on how
you have configured FAILOVER_MODE (session, select), you should find that very soon your database connection is alive
and you can continue working.
Fortuntely there is an easy fix: update the LOCAL_LISTENER parameter to reference the virtual address.
Oracle have a couple of notes on the issue (342419.1, 333159.1) and how to setup LOCAL_LISTENER. Note however, a the time of writing this (and I'm trying to get it fixed), note 342419.1 does not exactly describe the fix correctly.
It mentions to set the LOCAL_LISTENER using the command like this (where server tnsnames.ora has an instance-connect string using VIP address called 'LISTENER_LXDB0036' ):
Alter system set LOCAL_LISTENER= 'LISTENER_LXDB0036' scope=both;
However, this sets a server parameter that would be picked up on all instances. So there are actually two choices:
- change the tnsnames.ora file on each server to have a different, instance-specific definition of
'LISTENER_LXDB0036' , or
- I think the preferred way: set a SID-specific parameter by adding the SID parameter to the alter system command
(assuming the instance name is SVC1 in this case):
Alter system set LOCAL_LISTENER= 'LISTENER_LXDB0036' scope=both SID='SVC1';
Note that the listener registration is is only a problem if the database was created with a lister on default port. Haven't seen it myself, but apparently if you use DBCA to create a database with a non-default listener, then the LOCAL_LISTENER entry is explicitly set with correct reference to VIP.
So the message for today. If you are installing RAC or are responsible for managing a RAC database, I strongly suggest you swivel over right now and 'show parameter LISTENER'. Make sure you don't have an HA problem lurking in your system just waiting to bite you and the very worst moment!
Postscript: I submitted a request for change, and note 342419.1 has now been updated to reflect a more correct solution as of 25-Jun-2007.
Postscript 2: This issue is apparently addressed in 11g. Thanks for the report on this karlarao.
Postscript 2b: As Mark Twain would have said, "The reports of a solution are greatly exaggerated" - apparently 11gR2 still does not set a FQDN by default. Time to crack out a test...
read more and comment..
iX2007 day 2 pm - SOA track
![]() Ended up catching the SOA track
which was moderated and introduced by Ng Beng Lim from NCS. Oracle, Microsoft and BEA all had a failrly standard pitch
with a heavy emphasis on governance (although slightly different ways of modelling the overall journey).
Ended up catching the SOA track
which was moderated and introduced by Ng Beng Lim from NCS. Oracle, Microsoft and BEA all had a failrly standard pitch
with a heavy emphasis on governance (although slightly different ways of modelling the overall journey).
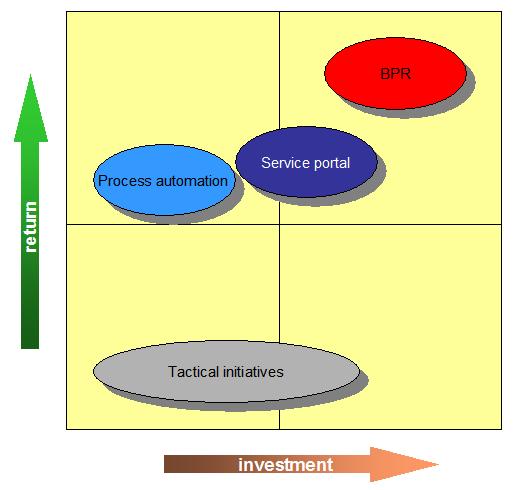
Jurgen Coppens (Accenture) did a refreshingly different approach with a focus on overall transformation (to be
expected;) but in particular value realization. Presented some good models, like my sketch to the right, and also
advocated a pragmatic approach of focusing on the quick wins in the early stage.
One impression I got from all the speakers however is that they all called for a rational architecture and governance
process that is strongly tied to business strategy. In fact this is a fundamental assumption. I have this impression
however that for many companies are not really ready to address the question of whether to adopt SOA or not, since they
are still have not established the foundation architecture and governance competency. Baby steps.
Anyway that's a wrap for the conference. As I mentioned in my first post, this was the first that had caught my eye for
some time, and it lived up to the promise.
ix2007
read more and comment..