Cryptonomicon
I've had my head in Neal Stephenson's
Cryptonomicon
for the past few weeks. Seriously, at a thousand-over pages, its not one to knock over in an evening.
But it is a fantastic tale. Actually more like three tales in one.
It makes me wonder how he does it. The writing is like stream of consciousness, and I guess it would need to be
judging how prolific he is (I haven't even started on the baroque cycle). Yet if mere mortals like you or I would
try this, I am pretty sure the result would be pure tripe.
Cryptonomicon is anything but.
I am dazzled and intrigued by the miscellaneous tangential twists and turns of the narrative, and the
incredibly inventive detail that scatter the way, like breadcrumbs leading to a safe haven.
Little things such as his similes.
.. dead-monitor-screen grey..Now isn't that brilliant? Surely deserves a named place in the CSS Color Palette if I were the judge!
And subtle digs that flit by if you are not paying attention.
"You know what that is? It's one of those men-are-from-venus, women-are-from-mars things"Oh so true.
"I have not heard this phrase but I understand immediately what you are saying."
"It's one of those American books where once you've heard the title you don't even need to read it," Randy says.
"Then I won't."Priceless!
read more and comment..
Half Share, Full Share and beyond...
|
After enjoying Quarter Share so much, I quickly
listened to the sequels Half Share and Full Share. They continue Ishmael Wang's career aboard the Space
Clipper Lois McKendrick in rollicking fashion. Honest to goodness
ripping yarns! I was sad to complete the trilogy, buoyed only by the hope that the author, Nathan Lowell, would continue the series. Well, this post is coming quite a while after I listened to the three stories, and it seems Mr Lowell has been busy. I was reminded to checkout the latest when I saw Podiobooks report that Nathan Lowell has taken a break from his own stories to narrate Time Crime by H. Beam Piper (iTunes downloading...) So of course I checked out Nathan's site - The Trader’s Diary - to discover Nathan has already completed another in the Golden Age series: South Coast. And its already #3 in the Podiobooks Top Overall Ratings chart. ...my iTunes is running hot now! |
  |
read more and comment..
drop.io - cool & effective "media" sharing
..I hesitate to say "file sharing" because it gets funkier than that. Record somthing on your phone, mail to your
drop.io drop, and it shows up as an enclosure on an rss feed = instant podcast!
The basics are solid - dead simple file sharing. First heard about this on net@nite; definitely worth checking out.
If - for some reason I can't think of right now - you wanted to send me a file, you can now drop it on my drop.io
widget:
read more and comment..
Using OVD Filtered Directories for LDAP Authentication
Oracle Virtual Directory (OVD) is one
of the little-known or understood hero products in the Oracle suite of
technology offerings [I put OEM Grid Control in the same class].
In this post I'm going to share a few thoughts on OVD, and present a few approaches for using OVD to present a
restricted view of information from another directory, and how that can be used to limit access to applications that
use an LDAP authentication mechanism.
When I was first learning about OVD back in early 2007, after the Oracle acquisition, it immediately grabbed my
attention. Simple, easy to use, but so powerful - a swiss army knife for anyone working in the directory management
space. Maybe that is the wrong analogy, because the greatness in OVD is that it doesn't try to boil the ocean - it just
does one thing, but does it really well.
Simply put, it allows you to combine directory-related information from disparate sources (LDAP, AD, database etc) and
present an LDAP-compliant view in real-time. And the virtual bit is
real (if that makes any sense) - OVD doesn't store anything, unlike a
meta-directory; it just passes through the directory requests according to the rules you setup.
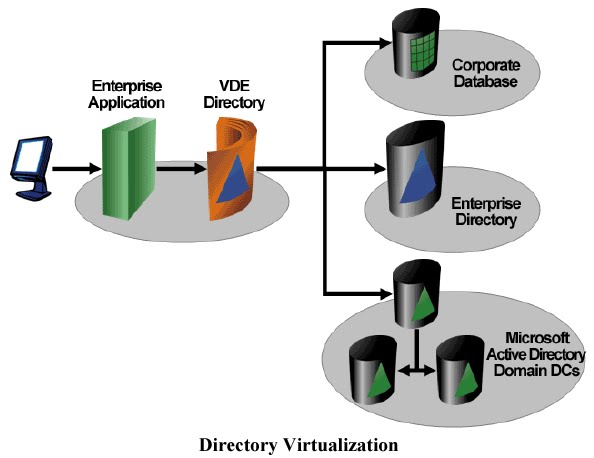
The virtual nature makes OVD ideal in large enterprise situations, where control of directories may be distributed.
Another group may have a directory that contains some information you want to use as part of your "directory view", but
are not going to cede any ownership or agree to any changes anytime soon, like adding some new attributes. Wheel in
OVD!
Likewise, affiliated companies may want to share directory information, but not handover control. And if the business
relationship comes to and end, the directory owners want to know that they can turn off access in a moment, without
needing worry about cached or replicated data left on the other side of the corporate divide. OVD to the rescue!
Case in Point: you need a subset of an existing directory
The inspiration for this post is a small challenge I was involved with recently. The company was deploying a new web application - just happened to be Oracle WebCenter Wiki, but the same applies to any application that supports LDAP authentication.The only directory available contained a mix of users - some who should be able to access the wiki, and some who shouldn't. Configuring the wiki authentication mechanism at the directory is simple - but it is an all or nothing proposition. And of course, we couldn't go change anything the directory itself.
Sounded like a job for OVD!
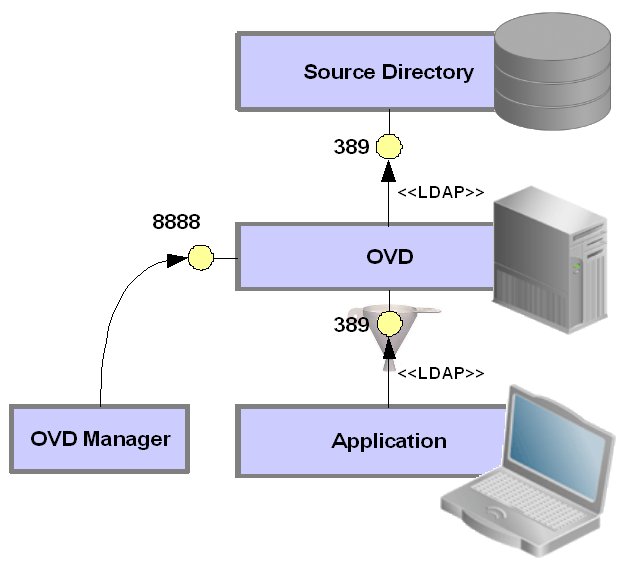
Here's the basic setup - OVD is deployed between our application and the main directory, like a proxy server. We want to OVD to effectively "filter" requests from the application.
Configuration of OVD is done using the OVD Manager client, which connects to the administration port of the OVD server.
Approach #1: DN Matching
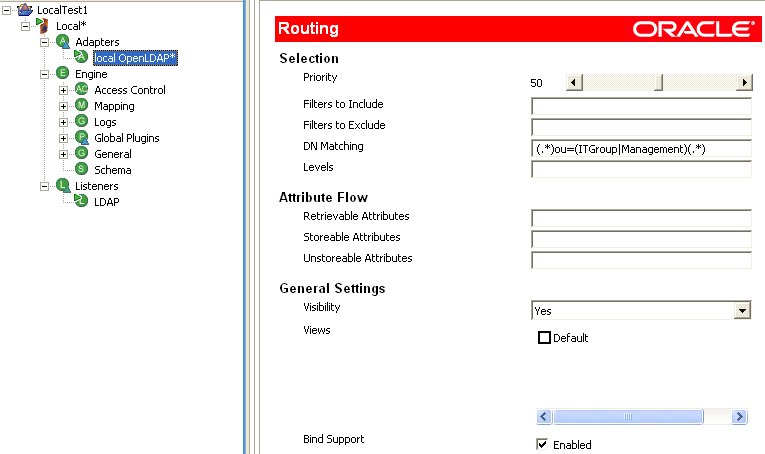
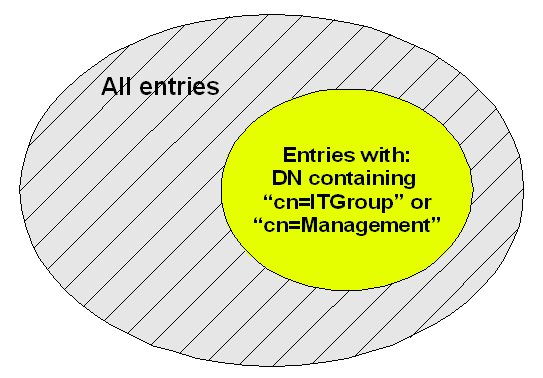 If you can define the
distinction between included/excluded entries in terms of an entry's DN, then a very simple solution is to use the "DN
Matching" property of the source adapter. This is fund in the Routing
configuration.
If you can define the
distinction between included/excluded entries in terms of an entry's DN, then a very simple solution is to use the "DN
Matching" property of the source adapter. This is fund in the Routing
configuration.Say for example, we only wanted our OVD directory to include entries that are in the ou=ITGroup or ou=Management containers. In this case, we would set the DN Matching property with a regular expression that will match on the DN string:
m/(.*)ou=(ITGroup|Management)(.*)/
Approach #2: ACL Restrictions
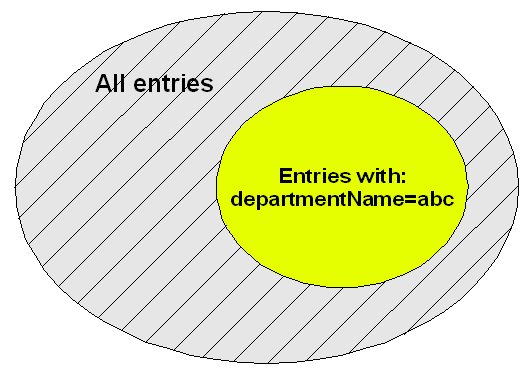 In practice, the DN may not
provide enough information to distinguish items to include and exclude, and it is necessary to discriminate on the
basis of an attribute, such as "departmentName". In this case, access control in the OVD engine may be configured to
restrict the directory view based on a suitable filter.
In practice, the DN may not
provide enough information to distinguish items to include and exclude, and it is necessary to discriminate on the
basis of an attribute, such as "departmentName". In this case, access control in the OVD engine may be configured to
restrict the directory view based on a suitable filter.Filter: departmentName=ITGroup
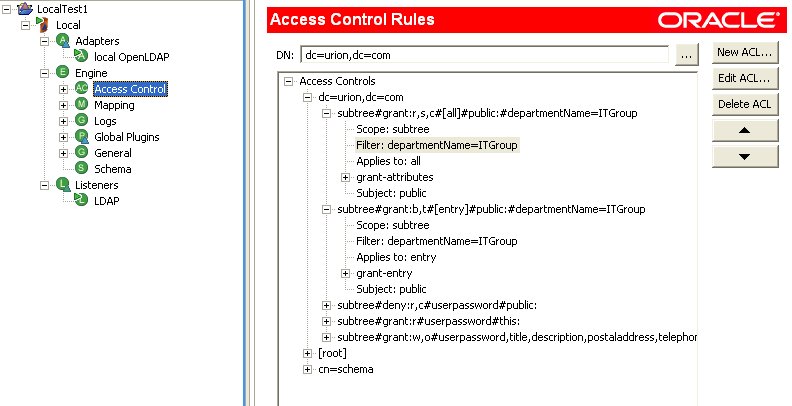
It is important to note with this approach that ACLs can be applied to all LDAP operations, except bind.
As a result, the directory view we have created with OVD appears to only contain the filtered subset of information: we cannot browse, serach, get or modify anything else. However, if you present a fully-qualified DN and associated password, it will authenticate and bind any entry that exists in the source database.
On spec, that seems to blow the whole approach out of the water. That's what I was thinking too, until Mark Wilcox helpfully nudged me along with a neat insight...
If our requirement is to use OVD to restrict the set of users that can authenticate via an application, we only need to consider the application authentication mechanism. In most cases, the process is similar to the one illustrated below. The user enters an id or username, which is used by the application to lookup the user's DN, which is then used to bind along with the user-supplied password. If the application can't find the DN in the first place, then no bind is possible.
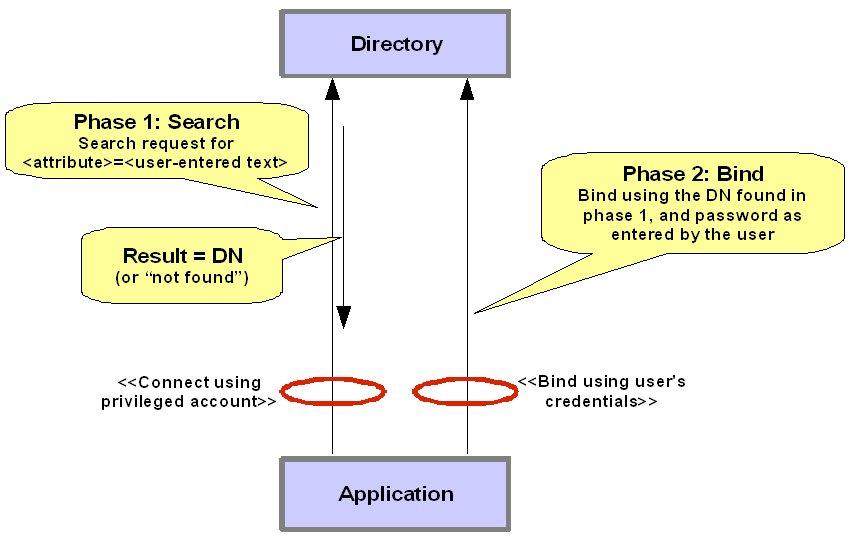
Of course, the acknowledged security "exposure" in this case is that a user can bypass the application and directly bind via OVD if they know their DN. However this is probably a false risk, because the user would have always had a similar capability with the source directory itself (assuming that the source directory and OVD are equally accessible to the user over the network).
Bottom line? Using ACLs to restrict the search effectively controls the set of users that the application can authenticate.
In Practice: Oracle WebCenter Wiki
Oracle WebCenter Wiki is thye example application, but you can think of it as any old J2EE application packaged as an EAR that supports Java SSO. By default it will use JAZN XML file-based storage for user accounts.When deployed in OC4J, the security provider used for the Wiki application can be easily changed via the Enterprise Manager web interface.
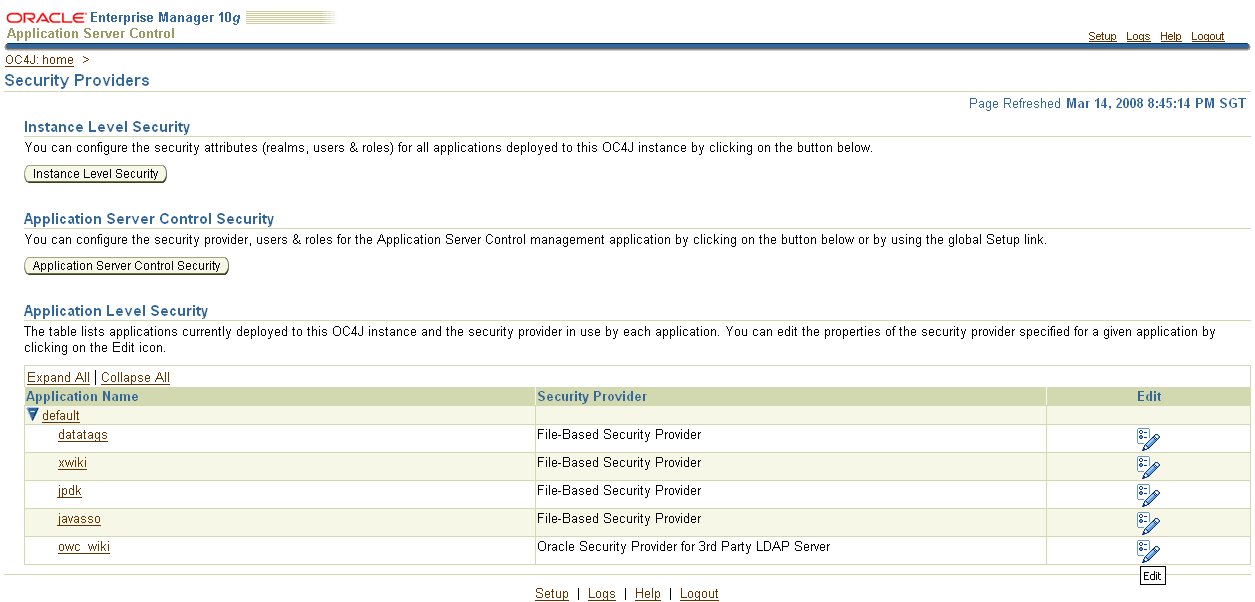
Switching to OVD as the authentication source is a simple matter of selecting the Oracle Security Provider for 3rd Party LDAP Server and configuring it with some simple directory details:
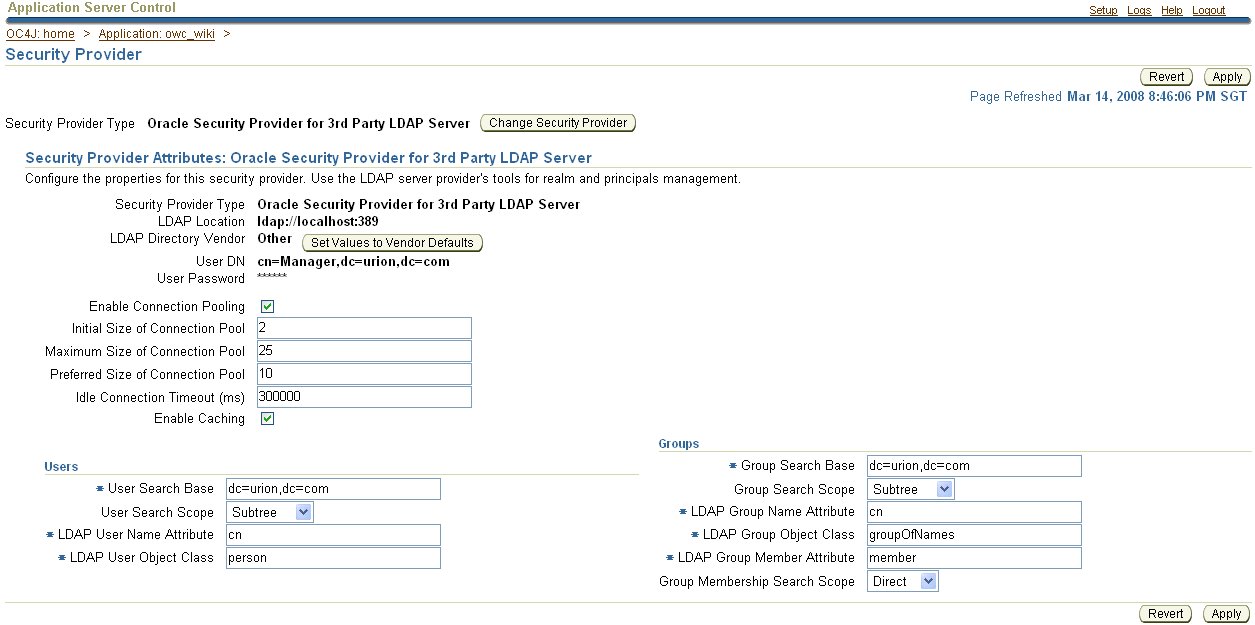
Almost done. There are two assumptions that I think the wiki makes about the directory. Just need to make sure these are setup:
- wiki users must be members of the group called "users"
- administrators are members of the group called "oc4j-administrators"
Now you are done. The wiki authentication is being performed against the limited set of users visible through OVD.
Caveat: selecting the Oracle Security Provider for 3rd Party LDAP Server causes the site to revert to basic authentication (i.e. popup a username/password dialog instead of using a web form). Not a big deal, but you will find the "logout" feature in the wiki now fails because it assumes form-based custom authentication. So once you have people lured into your wiki, they are trapped! ;-)
Wrapping Up
I've covered two techniques for restricting the set of information published via OVD: DN Mapping, and ACL Filters.There are other approaches that I've not covered here. For one, Java or Python plug-ins (a.k.a. mappings) can achieve the same result, as well as more complex behaviours of course.
These techniques allow OVD to be used to restrict overall access control for applications that use LDAP authentication mechanisms.
Once again, hat-tip to Mark Wilcox for his help when I thought I'd hit a wall while researching this topic!
read more and comment..