The top 10 dead (or dying) computer skills
I try to avoid postings that just refer you to other blogs or articles, but I've succumbed. ComputerWorld's
The top 10 dead (or dying) computer skills prompted a bit of nostalgia. I scored 91% [giving myself 1% for the time
I bought a book on COBOL while at uni ... and had the good sense to take it no further than that!!].
 OS/2 brings back memories, of
which I was also reminded when I first checked out Google's code search
and found some of my
1995 OS/2 code lying around! [NB: these days, I look at this code and shudder "Eek!... buffer overflow
vulnerability!!" ... security just wasn't front of mind back then! ]. But it also reminds me of how much thought I put
into the decision to adopt C++ on OS/2. It very much felt like "this is a decision that I'll live with for years". But
12 years later, in 2007, that decision-making process seems so naive and foreign. Now it is routine to dabble in a
couple of scripting languages, some Java, even some C++. The right (or most fun) tool for the job, right?
OS/2 brings back memories, of
which I was also reminded when I first checked out Google's code search
and found some of my
1995 OS/2 code lying around! [NB: these days, I look at this code and shudder "Eek!... buffer overflow
vulnerability!!" ... security just wasn't front of mind back then! ]. But it also reminds me of how much thought I put
into the decision to adopt C++ on OS/2. It very much felt like "this is a decision that I'll live with for years". But
12 years later, in 2007, that decision-making process seems so naive and foreign. Now it is routine to dabble in a
couple of scripting languages, some Java, even some C++. The right (or most fun) tool for the job, right?
If I could say "Programming Language Bigotry" is a skill (some people certainly practiced and honed it like it was),
then boy am I glad it seems to be a thing of the past and perhaps it deserves to be #1 in this list!
After a brief post-dot-boom hiatus, the dramatic rate of evolution is certainly back, spurred on by Web 2.0 hype. The
rate of technological change has indeed become so "normal" that a top 10 list hardly scratches the surface. Personally
I would have voted for int 21h. I'm sure generations to
come will have absolutely no idea what that means, but for me and presumably many others, I can sum up a year of
computer science with that very phrase.
For many (myself included), To Be Alive is To Be Learning and vice versa. The new religion if you
will. "Lifelong learning" or "learning for life" are too trite and miss the essential truth.
Other may say that to be continuously learning is to be in a perpetual state of childhood. Look at some of the toys we are learning about and maybe they have a point!
Postscript: I just re-listened to a WebDevRadio Episode 18 which reminded me that Coldfusion is not dead!! At least according
to the guys at Mach ii..
read more and comment..
Monitoring log files on Windows with Grid Control
The Oracle Grid Control agent for Windows (10.2.0.2) is missing the ability to monitor arbitrary log files. This was
brought up recently in the OTN Forums. The problem seems
to have been identified by Oracle earlier this year (Bug 6011228)
with a fix coming in a future release.
So what to do in the meantime? Creating a user defined metric is
one approach, but has its limitations.
I couldn't help thinking that the support already provided for log file monitoring in Linux must already be 80% of
what's required to run under Windows. A little digging around confirmed that. What I'm going to share today is a little
hack to enable log file monitoring for a Windows agent. First the disclaimers: the info here is purely from my own
investigation; changes you make are probably unsupported; try it at your own risk; backup any files before you modify
them etc etc!!
Now the correct way to get your log file monitoring working would be to request a backport of the fix from Oracle. But
if you are brave enough to hack this yourself, read on...
First, let me describe the setup I'm testing with. I have a Windows 10.2.0.2 agent talking to a Linux 10.2.0.2
Management Server. Before you begin any customisation, make sure the standard agent is installed and operating
correctly. Go to the host home page and click on the "Metric and Policy Settings" link - you should not see a
"Log File Pattern Matched Line Count" metric listed (if you do, then you are using an installation that has already
been fixed).
To get the log file monitoring working, there are basically 5 steps:
-
- In the Windows agent deployment, add a <Metric NAME="LogFileMonitoring" TYPE="TABLE"> element to
$AGENT_HOME\sysman\admin\metadata\host.xml
-
- In the Windows agent deployment, add a <CollectionItem NAME="LogFileMonitoring"> element to
$AGENT_HOME\sysman\admin\default_collection\host.xml
-
- Fix a bug in $AGENT_HOME\sysman\admin\scripts\parse-log1.pl
-
- Reload/restart the agent
-
- In the OEM console, configure a rule and test it
-
Once you have done that, you'll be able monitor log files like you can with agents running on other host operating systems, and see errors reported in Grid Control like this:

So let's quickly cover the configuration steps.
Configuring metadata\host.xml
Insert the following in $AGENT_HOME\sysman\admin\metadata\host.xml on the Windows host. NB: this is actually copied this from the corresponding host.xml file used in a Linux agent deployment.
<Metric NAME="LogFileMonitoring" TYPE="TABLE">
<ValidMidTierVersions START_VER="10.2.0.0.0" />
<ValidIf>
<CategoryProp NAME="OS" CHOICES="Windows"/>
</ValidIf>
<Display>
<Label NLSID="log_file_monitoring">Log File Monitoring</Label>
</Display>
<TableDescriptor>
<ColumnDescriptor NAME="log_file_name" TYPE="STRING" IS_KEY="TRUE">
<Display>
<Label NLSID="host_log_file_name">Log File Name</Label>
</Display>
</ColumnDescriptor>
<ColumnDescriptor NAME="log_file_match_pattern" TYPE="STRING" IS_KEY="TRUE">
<Display>
<Label NLSID="host_log_file_match_pattern">Match Pattern in Perl</Label>
</Display>
</ColumnDescriptor>
<ColumnDescriptor NAME="log_file_ignore_pattern" TYPE="STRING" IS_KEY="TRUE">
<Display>
<Label NLSID="host_log_file_ignore_pattern">Ignore Pattern in Perl</Label>
</Display>
</ColumnDescriptor>
<ColumnDescriptor NAME="timestamp" TYPE="STRING" RENDERABLE="FALSE" IS_KEY="TRUE">
<Display>
<Label NLSID="host_time_stamp">Time Stamp</Label>
</Display>
</ColumnDescriptor>
<ColumnDescriptor NAME="log_file_match_count" TYPE="NUMBER" IS_KEY="FALSE" STATELESS_ALERTS="TRUE">
<Display>
<Label NLSID="host_log_file_match_count">Log File Pattern Matched Line Count</Label>
</Display>
</ColumnDescriptor>
<ColumnDescriptor NAME="log_file_message" TYPE="STRING" IS_KEY="FALSE" IS_LONG_TEXT="TRUE">
<Display>
<Label NLSID="host_log_file_message">Log File Pattern Matched Content</Label>
</Display>
</ColumnDescriptor>
</TableDescriptor>
<QueryDescriptor FETCHLET_ID="OSLineToken">
<Property NAME="scriptsDir" SCOPE="SYSTEMGLOBAL">scriptsDir</Property>
<Property NAME="perlBin" SCOPE="SYSTEMGLOBAL">perlBin</Property>
<Property NAME="command" SCOPE="GLOBAL">%perlBin%/perl</Property>
<Property NAME="script" SCOPE="GLOBAL">%scriptsDir%/parse-log1.pl</Property>
<Property NAME="startsWith" SCOPE="GLOBAL">em_result=</Property>
<Property NAME="delimiter" SCOPE="GLOBAL">|</Property>
<Property NAME="ENVEM_TARGET_GUID" SCOPE="INSTANCE">GUID</Property>
<Property NAME="NEED_CONDITION_CONTEXT" SCOPE="GLOBAL">TRUE</Property>
<Property NAME="warningStartsWith" SCOPE="GLOBAL">em_warning=</Property>
</QueryDescriptor>
</Metric>
In the top TargetMetadata, also increment the META_VER attribute (in my case, changed from "3.0" to "3.1").
Configuring default_collection\host.xml
Insert the following in $AGENT_HOME\sysman\admin\default_collection\host.xml on the Windows host. NB: this is actually copied this from the corresponding host.xml file used in a Linux agent deployment.
<CollectionItem NAME="LogFileMonitoring">
<Schedule>
<IntervalSchedule INTERVAL="15" TIME_UNIT = "Min"/>
</Schedule>
<MetricColl NAME="LogFileMonitoring">
<Condition COLUMN_NAME="log_file_match_count"
WARNING="0" CRITICAL="NotDefined" OPERATOR="GT"
NO_CLEAR_ON_NULL="TRUE"
MESSAGE="%log_file_message%. %log_file_match_count% crossed warning (%warning_threshold%) or critical (%critical_threshold%) threshold."
MESSAGE_NLSID="host_log_file_match_count_cond" />
</MetricColl>
</CollectionItem>
A bug in parse-log1.pl?
This may not be an issue in your deployment, but in mine I discovered that the script had a minor issue due to an unguarded use of the Perl symlink function (a feature not supported on Windows of course).
The original code around line 796 in $AGENT_HOME\sysman\admin\scripts\parse-log1.pl was:
...
my $file2 = "$file1".".ln";
symlink $file1, $file2 if (! -e $file2);
return 0 if (! -e $file2);
my $signature2 = getSignature($file2);
...
This I changed to:
...
my $file2 = "$file1".".ln";
return 0 if (! eval { symlink("",""); 1 } );
symlink $file1, $file2 if (! -e $file2);
return 0 if (! -e $file2);
my $signature2 = getSignature($file2);
...
Reload/restart the agent
After you've made the changes, restart your agent using the windows "services" control panel or "emctl reload agent" from the command line. Check the management console to make sure agent uploads have resumed properly, and then you should be ready to configure and test log file monitoring.
read more and comment..
Validating Oracle SSO Configuration
A failing OC4J_SECURITY process recently had me digging out an old script I had put together to test Oracle Application
Server Single-Sign-On (OSSO) configuration.
How and where the OSSO server keeps its configuration is a wierd and wonderful thing. The first few times I faced OSSO
server issues I remember digging through a collection of metalink notes to piece together the story. It was after
forgetting the details a second time that I committed the understanding to a script (validateSso.sh).
 Appreciating the indirection
used in the configuration is the key to understanding how it all really hangs together, which can really help if you
are trying to fix a server config issue. Things basically hang together in a chain with 3 links:
Appreciating the indirection
used in the configuration is the key to understanding how it all really hangs together, which can really help if you
are trying to fix a server config issue. Things basically hang together in a chain with 3 links:
1. Firstly, the SSO server uses a privileged connection to an OID server to retrieve the OSSO (database) schema
password.
2. With that password, it can retrieve the SSO OID (ldap) server connection details from the OSSO (database)
schema.
3. Thus the SSO Server finally has the information needed to connect to the OID server that contains the user
credentials.
The validateSso.sh script I've
provided here gives you a simple and non-destructive test of all these steps. The most common problem I've seen in
practice is that the OSSO schema password stored in OID gets out of sync from the actual OSSO schema password. I think
various causes of these problems, but the script will identity the exact point of failure in a jiffy.
read more and comment..
Getting your Oracle Forum posts as RSS
In my last post I said one of my "Top 10" wishes for OTN was to
be able to get an RSS feed of posts by a specified member to the Oracle
Forums.
At first it may sound a bit narcissistic to have a feed that allows you to follow what you have written yourself!
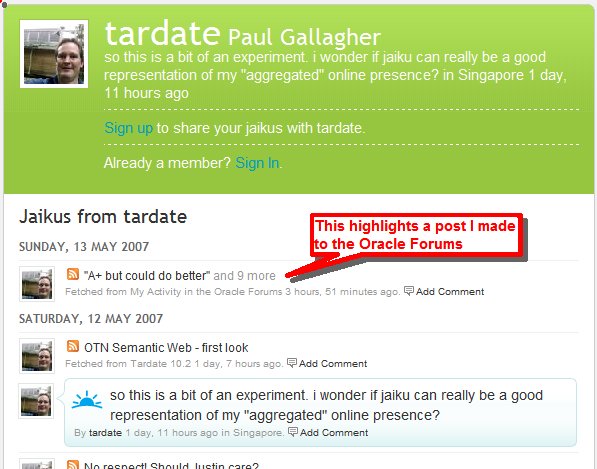 It was my exploration of
Jaiku that prompted the thought. Since "presence" is their big thing, I've been
experimenting to see what's its like to have Jaiku aggregate all your web activity. So far it looks really cool - I
love the interface. Must say that I'm not sure how useful Jaiku may turn out to be in the long run ... I suspect it
works best if you have a whole lot of your friends also using it. NB: the Jaiku guys are particularly focused on mobile
phones. Its not something I've tried yet because I think it would be a bit ex from where I live.
It was my exploration of
Jaiku that prompted the thought. Since "presence" is their big thing, I've been
experimenting to see what's its like to have Jaiku aggregate all your web activity. So far it looks really cool - I
love the interface. Must say that I'm not sure how useful Jaiku may turn out to be in the long run ... I suspect it
works best if you have a whole lot of your friends also using it. NB: the Jaiku guys are particularly focused on mobile
phones. Its not something I've tried yet because I think it would be a bit ex from where I live.
So Jaiku was the catalyst for me thinking about getting an RSS feed of my forum posts. Recently I've been trying to
make an extra effort to contribute to the forums; frankly, they've always seemed a little quieter than I think they
should be. So seeing any forums posts I make highlighted on Jaiku should be one of the neat indicators of my "web
presence".
Problem is, while you can get a web page that lists your recent posts, and you can subscribe for email alerts when
authors post, I wasn't able to find a way of getting an RSS feed for a specific author's posts.
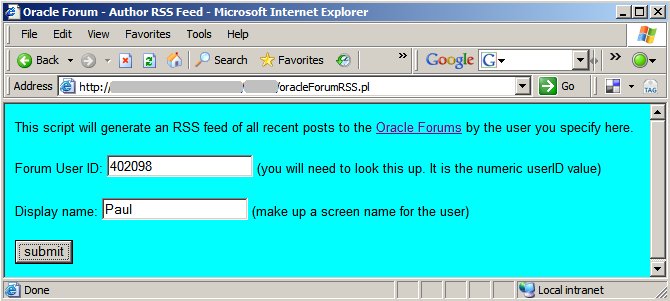 So I created a little perl
script that scrapes the HTML and generates an RSS feed (using XML::RSS::SimpleGen). I've packaged it as a CGI program
on a server I have access to. That's what I registered on my experimental Jaiku
site, and it works like a charm.
So I created a little perl
script that scrapes the HTML and generates an RSS feed (using XML::RSS::SimpleGen). I've packaged it as a CGI program
on a server I have access to. That's what I registered on my experimental Jaiku
site, and it works like a charm.
Until Oracle build this feature into the forums, feel free to take my oracleForumRSS.pl script and
experiment away. Its pretty basic, but is generic for any forum user and ready to go. Sorry, but I'm not hosting it for
direct use by others, so you'd have to find you own server with cgi or convert it to script that spits out a static rss
xml page instead.
Post-script: Eddie Awad blogged on the "Easy
Way" to do this using Dapper. Very cool, thanks Eddie!
read more and comment..