LLM Limits: GPUs or Data?
Large Language Models (LLMs) are statistical inference machines that project from available data and training sets. When they stray beyond the data, they hallucinate. Which may be a good thing, depending upon your intent. But usually not. LLM advances in the past 10 years have largely been constrained by the capital and supply-chain wizardry required to put farms of GPUs on the job of training the latest model. But are we reaching the point where DATA becomes the strangling bottleneck, not GPUs?

The Bait And Switch
Remember the early days of AI hype, promising to cure cancer and solve climate change?
Well, … no. Things are a lot more prosaic these days.
In his 2026 presentation to the Royal Society, Professor Michael John Wooldridge explained how the LLM breakthroughs of the past 10-20 years really just boil down to the ability to apply scale (i.e. lots of GPUs and storage) to a simple and elegant idea - the transformer.

What was the training data that the model builders were using? Andrej Karpathy famously characterised model training as a lossy compression of the Internet.
While Common Crawl remains a good starting point for experiments, leading efforts such as OpenAI GPT-family models are trained on combinations of:
- Public web data
- Licensed data
- Human-created data
- Code repositories
- Books and reference materials
- User interactions
Which sounds great. All of human knowledge in a bottle!
But not quite.
I’ve noticed that people in tech, especially, over-estimate the completeness of the Internet. After-all, the early Internet cultivated an apparently self-evident truth that information wants to be free
.. as documented by Steven Levy in Hackers: Heroes of the Computer Revolution.
So how much information, and more importantly knowledge, is readily machine-reasonable? Some may be surprised that is is still a relatively small fraction, likely <5–10% of all recorded human knowledge.
If you include all tacit knowledge: far less than 1% is represented.
A quick thought-experiment may help:
Think of your last job, and the key activities you were occupied with to be successful day-to-day. How much of that was captured, written down, and stored somewhere?
For most people, even in very digitized roles, the answer is somewhere between “none” and “very little”. And that is how much data the AI has to work with.
Does it matter though?
A casual interaction with an LLM may appear satisfactory. That may be a low bar, as the roasting that Richard Dawkins got for his Claude Delusion illustrates.
My retrospectively-enlightening career is festooned with examples of good intentions boldly proceeding before an absence of data. To wit…
Skinny Data
Data, though rich an voluminous, does not contain the necessary detail
I recall conducting a machine-learning exploration on 12 years worth of customer support data. Multiple gigabytes of valuable digital dust.
It was successful to a degree: the model could predict resolution categorization with a high degree of confidence.
But it couldn’t determine exactly how to resolve a given case, because the actual technical steps and details were not recorded in the dataset.
So if you wanted to build an AI replacement for the support agent with this data, what you’d get would go something like this:
Customer: I seem to have problem X with these symptoms Y and Z. Can you help?
AI: Of course we can! Based on my training data I can confidently say that our resolution would be “Network Configuration”
Customer: er, ok? So what exactly should I do?
AI: You are right, perhaps my instructions were not clear. If you need further help, call our interactive voice-assisted ChatBot at 1-800-FUCK-OFF. I am sure they will be able to resolve your inability to follow our instructions
As the basis for anything remotely useful or intelligent, it turned out that the data was pretty much useless.
The data-capture challenge was that much of the real action happened “off-screen”. If the support agent needed to swivel and ssh into a remote device … totally transparent. Or consult with a colleague … unrecorded. Or use an air-gapped device to do some queries .. unmonitored.
It’s almost as if 90% of the job did not leave a digital footprint.
Correct!
And that was for a technical job. Imagine how much of a non-technical job fails to leave the digital footprints that an AI requires. 98+%?
Key learning:
Most “jobs” do not leave a meaningful digital footprint. If you want to capture the details, you will need a specific data capture initiative.
Meta may have belatedly wizened up to this deficit in their datasets, before it was revealed that they would start capturing employee mouse movements, keystrokes for AI training data.
Shadow Data
The data is out there, but it can’t be accessed
I’ve noticed this is a particular problem with historical research, as an example.
If one is looking for specific information, such as aircraft tail codes and operations logs, or uniform details for specific information, the information may exist somewhere - but it is in a book on a shelf, in a museum, library, or archive, and definitely not part of the training data, or accessible by search.
AI responses on such topics will be lacking in the necessary detail, or worse, fictitious.
If one were to ask, for example, about the uniforms worn by the Japanese in Peleliu, we get:
- Olive-drab or khaki cotton tunic and trousers
- Often faded to light brown, tan, or greenish-grey from tropical exposure
- Many wore simplified tropical shirts instead of full tunics
- Puttees (cloth leg wraps) or canvas gaiters
- Split-toe tabi shoes or hobnailed ankle boots
i.e the equivalent of
y’sir, he kinda looked japanese
Not useful! There is a great deal of information that is not generally accessible, or yet to be digitized. Rather than deliver glib deceptive answers, it would be far better if the concerned agents were able to promote relevant digitization efforts.
Data Black Hole
No-one thought to collect that data yet
Early in my career, I was involved in projects to improve predictive machine maintenance.
The problem was: the machines didn’t produce any data.
So the first step in most projects was to figure out what data you really needed, and how to collect it. It was usually a non-trivial exercise in itself; often the bulk of the dollars spent.
And these projects were successful, but for very bounded problems.
These days, people often assume the data is a given, or simply subject to a price for access being agreed.
But no. So much or the world remains inaccessible to machine-reasoning.
Key learning:
Do not underestimate the challenge of capturing “all the data”.
The Best Datasets
Hang on, I thought we were supposed to be curing cancer, solving climate change, or something equally important?
But no, we’re optimising software development instead!!!!
It is no surprise that “coding” is the domain within which AI agents got really good.
Coding presents the most complete and self-contained dataset, with much of the technical field available for AI training from books, blogs, and open source repositories such as LeetCode-Solutions, and an almost infinite selection of example TODO list implementations.
So we proclaim “job done”! … before remembering we were meant to be solving more important problems.
Are we selecting the best data to solve the most important problems, of finding the easiest problem that the most available data can solve?
Remember 2015, the year the world declared developer productivity as the most imminent threat to humanity?
Wait, no! It was water crises and interstate conflict.
Has AI helped solve those problems? Well, no…
But At Least AI Can Code
Hmm, AI still falls short at just generating code.
In my experience, the biggest challenge in software engineering is “figuring out what people want/need”.
Call it requirements analysis, UX design, or just consulting - bringing clarity to the messy mix of inter-personal and business incentives was always the more critical (and challenging) part of project.
The part that AI is far from being able to master.
Where To From Here?
More Data
If we pursue the LLM paradigm, then clearly what we need is more data.
Current LLMs, no matter how good they appear to be, are working on datasets that represent less than 1% of all knowledge.
But all the easily accessible data has already been plundered.
QED: LLMs need a massive data collection exercise, like Meta’s MCI.
But surely this as an exponential race to the bottom? As fast as GPUs can process, we need even more data to ingest. I am picturing a lecturer’s chart scooting off to the top-right…
Unbounded by Data
Or perhaps LLMs are an evolutionary dead-end?
Ineffable Intelligence was founded by David Silver in November 2025 to chart an alternative path: focus on developing reinforcement learning algorithms that would have the ability to endlessly discover knowledge and skills, rather than the transformer approaches that are fundamentally bounded by the data they have available.
Translated, I believe this simply means:
- rather than just work on data we are given
- we will go collect data for ourselves
Presumably with suitably Black Mirror-esque data appendages and sensors to cross the machine-ecosystem boundary.
Composability
I’ve been increasingly drawn to the concept of job composability as a way of thinking about AI impacts on the workforce.
Task composability is a design principle where complex workloads are broken down into smaller, independent, and reusable “tasks” that can be easily combined or reconfigured to create new workflows.
Most AI pitches assume they can do the “whole job”. But real people know this is BS.
So the question becomes: can AI do a little bit of the job, and a human do the rest?
It depends on whether the task is composable or not.
A good example of a composable task could be content marketing: an AI can independently take care of Research & Data Gathering, while a human can take care of selecting appropriate sources and tailoring the pitch for the client.
Typical characteristics of non-decomposable tasks:
- Lack of Objective Truth: Tasks where the “correct” answer depends entirely on subjective human values. e.g. writing a sympathy card for a friend
- Tacit Knowledge: Skills that are learned through physical embodiment rather than data. e.g. how to master kigumi
- High-Stakes Accountability: Roles where a human must “own” the moral consequences of a decision. e.g. someone must be on the line for this forecast call!
Conclusion
So this is the rational middle-ground: LLMs are not worth the trillion dollar valuations, but they can be useful in the routine course of working a task.
I just hope that someone gets stuck with that AI training bill, like the investors who paid for the Global Crossing bankruptcy and unwittingly ushered in the era of “effectively free” global communications!
read more and comment..
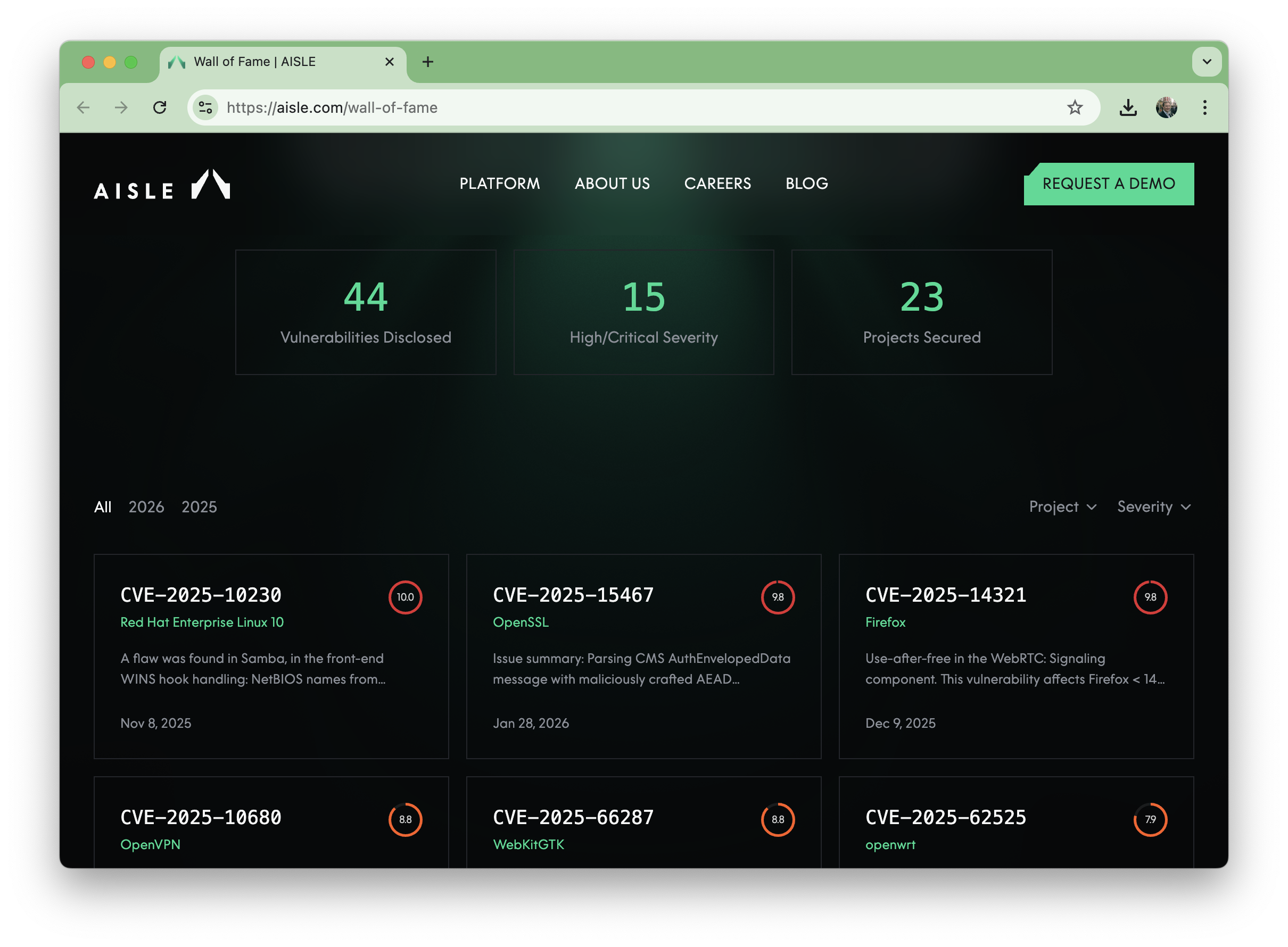
AISLE: The End of Zero-Days?
AISLE have been developing a complete AI workflow for deep cybersecurity discovery and remediation,
and if their Wall of Fame is any indicator of potential,
they may prove to be one of the most transformative companies to emerge from the AI bubble.
I must admit to being a little jaded. Where are all the AI startups delivering meaningful breakthroughs?
We were sold a vision of AI curing cancer, ending the climate crisis, and eliminating poverty.
Instead, much of the commercial narrative seems to have fixated on workforce reduction and generating a tidal wave of AI slop, along with a huge power bill.
So I wasn’t expecting to be impressed when I heard about AISLE on Security Now #1063.
But I was.
It’s 2026, and we still treat vulnerabilities as “Normal”
Since computing’s original sin of mixing code and data, security has been a cat-and-mouse game. We’ve made enormous advances in system and network security, yet we still accept one assumption as inevitable:
There is no such thing as bug-free code.
As developers, we follow secure coding practices. We run static analysis. We adopt DevSecOps pipelines. And still, vulnerabilities ship.
Our experience with AI coding tools such as Claude Code and GitHub Copilot is mixed. They fix some bugs, hallucinate others, chase red herrings, and lack a true closed-loop workflow for discovering and eliminating security flaws.
What is AISLE doing differently?
AISLE’s ambition is simple and radical: software released with zero known security vulnerabilities. Where software is assured by AISLE to be free from security vulnerabilities before it is released.
The company emerged from stealth in October 2025. In the absence of reliable cybersecurity benchmarks, they targeted live, heavily audited open-source projects including:
- OpenSSL
- curl
- Firefox
- Linux
- OpenVPN
The results have been remarkable:
- OpenSSL security patch of 2026-01-27 addressed 12 new zero-day vulnerabilities - all discovered and remediated by AISLE
- curl 8.18.0 released January 8, 2026, AISLE was responsible for 3 of the 6 CVEs
If accurate, that’s not incremental improvement. That’s industrialized vulnerability discovery and remediation.
AISLE appears to be succeeding not by building a better autocomplete engine, but by creating a full AI-driven workflow dedicated to one problem space.
Is “Zero Vulnerabilities” Realistic?
For many of us versed in the “old ways”, this sounds too good to be true! And to be sure, if software is free from security vulnerabilities, that is not the end of security issues.
Even perfect code doesn’t eliminate phishing or credential theft. Humans will always remain part of the attack surface.
But removing exploitable software flaws changes the economics of cybercrime dramatically. No zero-days means fewer catastrophic breaches.
Another AI Unicorn?
AISLE emerged from stealth backed by angel investors. No major institutional round or valuation has been disclosed yet.
But if their trajectory continues, they may become something rare: not the first AI unicorn, but possibly the first AI unicorn to actually do something significantly good for the world!
What Happens Next?
The obvious path is integration into CI/CD pipelines with a security assurance as a subscription service. One can request a demo, but I’ve not yet seen any pricing.
Longer term? Pure speculation, but I would not be surprised to see a rapid exit and acquisition. My bet would be Microsoft:
- to use internally:
- A world without Windows security patches, because there are no vulnerabilities to fix!
- to integrate with Microsoft-owned GitHub as a value-added service:
- A perfect pairing or upgrade to the existing Dependabot and Code Scanning services
- A must for enterprise clients, while ensuring the open-source supply chain that so many companies rely on is kept free from issues
If AISLE can assure software security before release, “reasonable industry practice” changes. Releasing vulnerable code may eventually be considered negligent under the law, with the old “no liability” boiler plate in license agreements challenged in court. Be prepared to defend why you are not using a service like AISLE!
References:
- aisle.com
- AI found 12 of 12 OpenSSL zero-days (while curl cancelled its bug bounty)
- Security Now Episode #1063
read more and comment..
AI in the Call Centre
AI is decimating call centres, but two can play at that game!
Inspired by true events😂

read more and comment..
Tyranny of the Urgent
The Agile Embedded Podcast is as thought-provoking as ever with their take on the Tyranny of the Urgent. The discussion focused very much on how the agile mantra of creating immediate customer value can lead a team astray, but it made me think of all the other ways I’ve seen and experienced the “Tyranny of the Urgent” over the years.
Three thoughts came to mind:
- We’re Not Being Honest about Impact and Urgency
- We are ignoring the Full Feature Lifecycle
- When Things are Always Urgent, it may just be a Capacity Problem
Tyranny of the Urgent: An anti-pattern where short-term urgent demands systematically override long-term important work, causing reactive behavior and worsening future urgency.
Problem 1. We’re Not Being Honest about Impact and Urgency
Task priority should be a factor of both Impact and Urgency. This is as true in agile environments as elsewhere. It’s a common prioritisation technique that appears in many guises (in project management, ITIL support, Eisenhower matrix, PICK Charts) but as a concept is trivially simple.
No matter how a team calculates priority, it is very sensitive to the fact that both impact and priority are hard to quantify and extremely subjective.
In reality, I’ve often had to deal with, let’s say “misleading”, assessments of impact or urgency. For example:
- the product owner claiming a feature is critical based on an imaginary concept of the customer
- i.e. trust me, I know what the customer needs without any data or actual customer input to back it up
- it can be a symptom of a team that is far past their initial requirements efforts and is now coasting.
- Solutions?
- without being rude about it, find a way to reset expectations around validating requirements before they are accepted for development.
- Discuss the “definition of done” for a story/requirement itself.
- May need a jolt to re-engage meaningfully with the customer group, perhaps with a new round of focus group, customer surveys, or customer visits.
- a sales person claiming features are deal-breakers for a new customer and must be urgently delivered to close the sale
- sometimes this may be true, but in many cases I’ve discovered it’s not (most painfully, after the fact)
- it may be “lazy sales”: passing the buck to development rather than do the hard work of selling the solution as-is and overcoming customer objections
- but it can also be a skills gap: sales or pre-sales don’t know the solution well enough or have the requirements analysis skills to help best assess the solution fit and gaps for the customer
- Solutions?
- the main way I found to battle this is greater involvement of development in the pre-sales process, proposal design and review.
- it may point to a lack of training on your product with the sales, pre-sales, or customer care teams
- whatever the C-suite says this week is the most urgent and important thing to work on
- i.e. if you have the authority, you can bypass whatever process is in place for product management
- This can be tough, because at the end of the day “the boss is always right”!!
- I’ve mainly seen this in places where senior management either don’t understand the processes used to manage product development, or they don’t trust it to deliver the necessary results
- Solutions?
- invest time in building the stakeholder relationships and educating them on how development works.
- nothing beats a good track record to build trust.
- if execs only hear about development when things go wrong, they’ll think that’s the norm
- make sure to provide regular updates that include all the good news about the process working correctly
Problem 2. We are ignoring the Full Feature Lifecycle
The podcast did touch on the Three Horizons model for ensuring there’s always an innovation pipeline, but on a smaller scale I’ve seen insufficient attention paid to appropriately balancing effort across the full lifecycle of features.
The most common anti-pattern I’m sure we’ve all seen is all effort consumed on new feature development, and only allowing for some effort to be clawed back to fix bugs. The team ignores the important work of taking features from good to great, and never gets around to retiring features that no longer add value.
I’m my own practice I’ve found “4Rs Feature Lifecycle Analysis” a very useful diagnostic to combat this. In essence, all stories get classified as belonging to one of the four stages of a feature lifecycle:
- Stage 1, Reveal: new feature development
- Stage 2, Refine: improving a feature
- Stage 3, Rectify: fixing bugs, CVEs, updating dependencies etc
- Stage 4, Retire: removing the feature when it no longer has sufficient value
Looking at where effort is bucketed makes it very clear if the product management process is delivering a pipeline of work that matches the maturity of the product. i.e.:
- during initial product development, one expects most effort to go into new feature development
- after launch
- if one is not seeing a shift towards refinement, it may indicate we are stuck in “new feature mode” and are not taking the time to improve the “v1” features already launched
- and if we see rectification starting to swamp feature development, it may indicate systemic quality issues
- in very mature products, we’d expect to see effort largely shift to rectification and ideally an uptick in retirement effort
If we are using agile software development process, isn’t Feature Lifecycle Analysis redundant? A well-balanced and high-performing team should be able to find the optimal balance by trusting the process:
- customer/business requirements rule, and are represented in the team through a product owner or even an onsite customer
- we prioritise work for each iteration as a team, balancing customer/business requirements with other things that the team knows are important in order to meet customer expectations (like performance)
- we keep our iterations short and continuously deliver working software, so even if we get things wrong we can course-correct in short order
That is of course the ideal. But we operate in the real world, and many things can upset the balance. For example:
- Urgency Trumps Impact
- It’s easy to find a queue of people ready to argue for the latest urgent requirement, but there’s no-one around to champion the more impactful stuff that hasn’t also been called out as urgent. Result? Six months later, we’ve delivered all the urgent things, but 90% of the potential impact (“value”) is still on the table.
- The New Shiny
- The new shiny trumps last week’s idea. This can be a problem in startups where the founder/ideas person is also the product owner. Excellent at generating new ideas, but no time or ability to follow-through. So the team leaves a trail of half-baked implementations but never seems to achieve anything great.
- Uninspired Leadership
- The team is looking for insight and vision to drive priorities but just hears “meh”. So the results are naturally also meh.
- Unreal Priorities
- A product owner who is (consciously or not) skewing priorities towards a certain theme or faction over all others, like one particularly vocal customer. Or perhaps lacking real customer insight, priorities are out of touch with reality.
- Weak Team
- A weak development team that’s not able to put up a convincing case for something they believe is important.
- Domineering Team
- Conversely, a development team that is too strong and always manages to spin the product owner to their way of thinking.
- Group Think
- Although we use a strict planning game to prioritize stories, the team is suffering from “group think” and priorities end up skewed to one point of view.
- ScrumMaster At Sea
- A scrum master that doesn’t recognise there’s an issue of balance until it is too late, or is running out of tricks to help the team fix it.
Feature Lifecycle Analysis is really just a diagnostic that can present in a picture what may otherwise just be a gut-feeling that something is not quite right.
Problem 3. When Things are Always Urgent, it may just be a Capacity Problem
We refined our scope to death, optimised all our processes, fine-tuned our tools, made all the improvements surfaced by our retrospectives, ensured all our people are well trained and working at their best… BUT we are still consistently failing to meet expectations for feature delivery.
We may just need to admit we have a fundamental capacity issue, and no amount of clever scheduling can plan our way out of the hole. Are we trying to do the work of an 8 person team with a team of 3?
If that’s the case, frankly it’s time for leaders to step up and either:
- reset expectations with stakeholders
- or make the case for investing in greater capacity
Listen to the Podcast
Yes, it is an old episode from 2023 but no less relevant for the fact. I’m busily catching up on back episodes;-)
read more and comment..